昨天一樣分步驟將 Multi-head attention 程式講解完了,比較麻煩是維度處理,但如果看懂就沒有太大問題了。
參考文章: https://www.cnblogs.com/rossiXYZ/p/18758992
https://github.com/jingyaogong/minimind/blob/master/model/model_minimind.py#L127
當我們學完了最基本的 Multi-head attention,此時就跟昨天說的一樣,可以看一下人家的程式是怎麼寫的,拿我們第二天跑起來的訓練來看,你會發現基本上有六七成像,不過有些名詞還沒看過,比如說 apply_rotary_pos_emb, kv_cache, repeat_kv, attention_mask,這我們之後會一個個慢慢講,但你會發現原本從不會,到現在已經看懂六七成。
核心觀念: 能進行 batch-processing
padding 的目的: 在訓練時每筆資料可能長度不一樣,比如音檔長度或者文字長度不同,但我們一個 batch 的資料長度大家要一樣,所以要有一個對齊讓長度一致。
padding 在實作上面簡單分兩種
基本上有 padding 就會有 padding mask,在計算 metric 時會將 padding 的地方忽略掉,才能得到正確的評分等等。
以上是對語音方面的做舉例,語音通常會對音檔或聲音特徵做 zero-padding,以下我們講一下 LM 方面以及 mask 觀念。
核心觀念: 紀錄哪些位置是 padding → 防止模型受到 padding 影響
一樣我們先來張圖片,再來講解
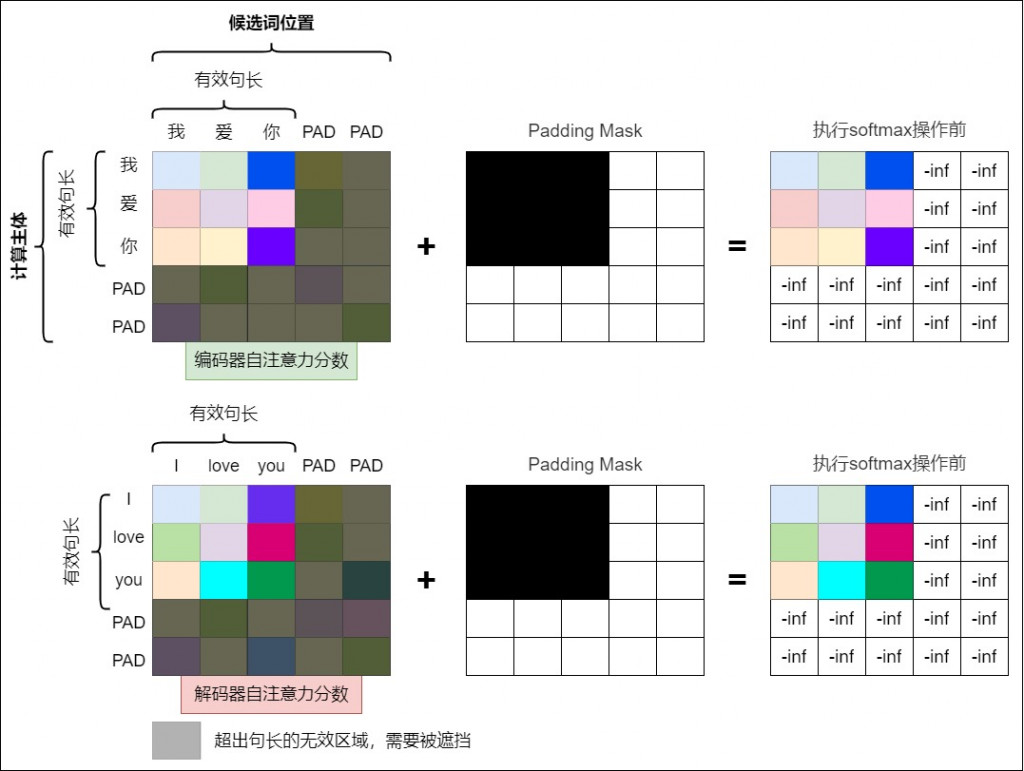
這裡先來一個最簡單的實作,主要就是用到 masked_fill,這裡 padding_mask 事先寫好,通常會需要自行處理。
import torch
def mask():
'''
比照上圖,假設文字輸入: [
["我", "愛", "你", <PAD>, <PAD>],
["今", "天", "天", "氣", "好"]
]
'''
B, H, L = 2, 2, 5 # (batch, n_head, seq_len)
attn_scores = torch.rand(B, H, L, L) # 模擬之前 MHA 的 scores
# 對應上面的 Step 1: 紀錄位置
# (B, L), True = padding 位置, False = 有效 token
padding_mask = torch.tensor([
[False, False, False, True, True],
[False, False, False, False, False]
])
print(f'mask 之前:\n {attn_scores}')
# 對應上的 Step 2: 填入很大的負數
# (B, 1, 1, L) -> (B, H, L, L)
attn_scores_masked = attn_scores.masked_fill(
padding_mask[:, None, None, :],
-1e9
)
print(f'mask 之後:\n {attn_scores_masked}')
attn_weights = torch.softmax(attn_scores_masked, dim=-1)
print(f'softmax 之後:\n {attn_weights}')
if __name__ == "__main__":
mask()
今天就先到這裡囉~ 明天我們繼續講另外一種 mask。


 iThome鐵人賽
iThome鐵人賽